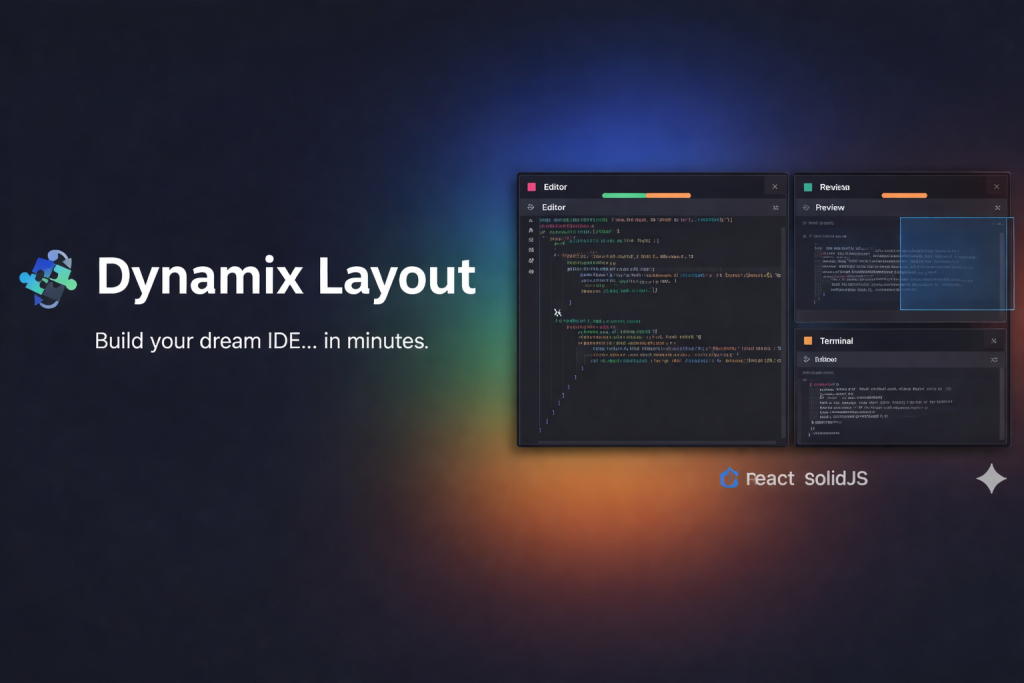
UncategorizedReverse-Engineered IDE-Grade Drag & Drop: Built a Framework-Agnostic Layout Engine akashaman / January 31, 2026 Explore how curiosity and reverse engineering led to a high-performance, open-source drag-and-drop layout engine.
UncategorizedFrom jQuery Spaghetti to React: 600% Faster WooCommerce Using Hybrid WP + React akashaman / January 19, 2026 Explore how a legacy WooCommerce site evolved from jQuery chaos to a fast React-powered hybrid stack.
UncategorizedHow I Made Bulk Ordering 1200% Faster with Multithreading! akashaman / February 3, 2025 Built a multithreaded scheduler with queuing, slashing processing time 1200% 🚀.
UncategorizedInside My Workspace: A Guided Setup Tour akashaman / May 9, 2024 Explore my workspace in Inside My Setup Tour—where every tool has a story and creativity knows no bounds.
UncategorizedThe Portfolio 🚀 akashaman / May 1, 2024 Unraveling the Architectural Odyssey of My Portfolio Development.